Gute Metadaten und OER-Verlag am Beispiel von ZUM.de
Das OER Sommercamp 2023 ist vorbei, und wir können mit Stolz sagen, dass der Workshop D ein schöner Erfolg war. Unser Ziel war es, ein technisches Thema zu erkunden und gleichzeitig die OER-Community in den Mittelpunkt zu stellen. Dabei stellen wir dir nun vor was es mit den guten Metadaten und OER-Verlag auf sich hat. Sei gespannt.
Gute Metadaten
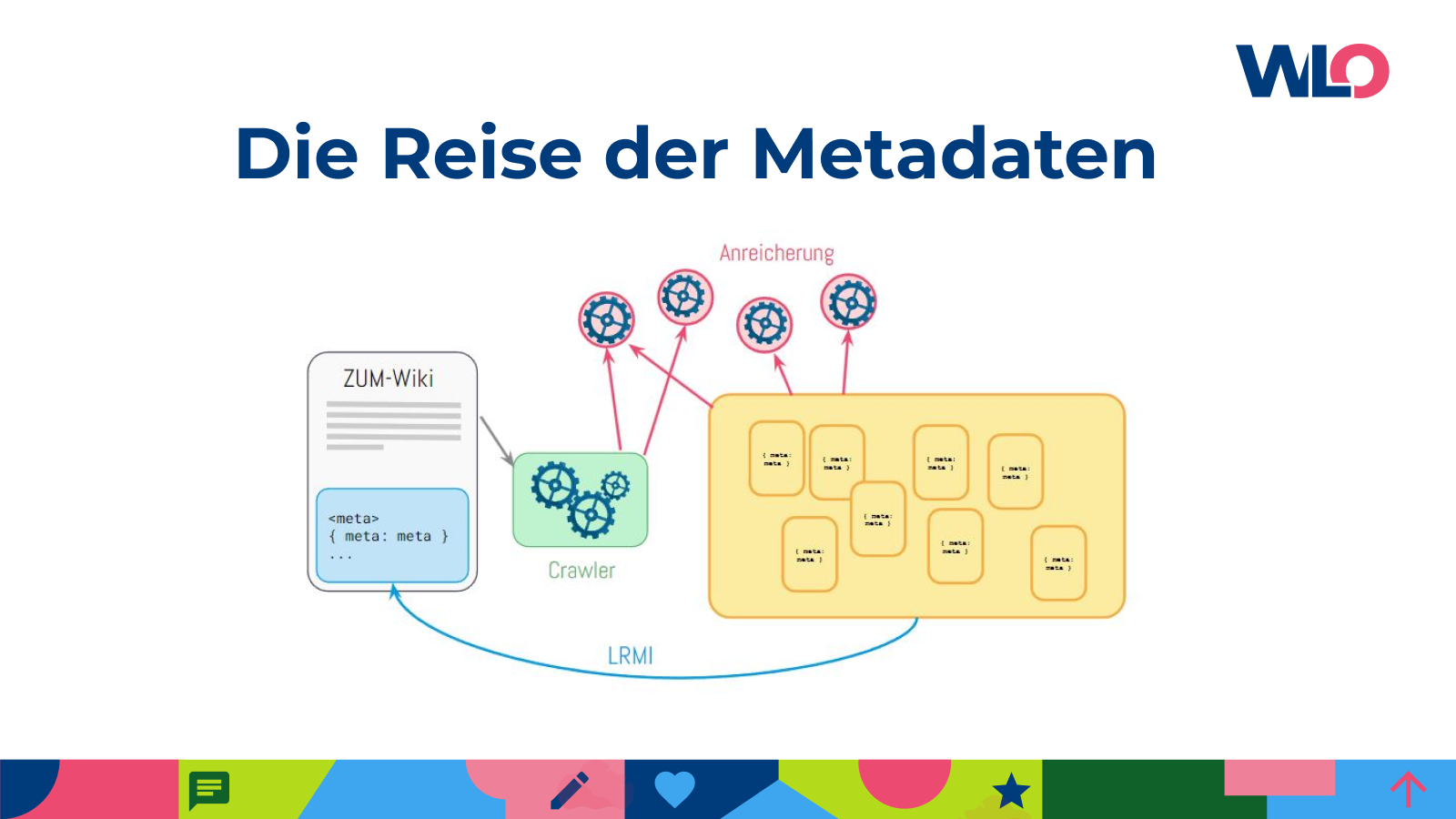
Eine wichtige Aufgabe von WirLernenOnline als Metadatenkonsolidierungsservice ist es, Metadaten zu sammeln, aufzubereiten und zu verbessern, um sowohl den Wert als auch die Auffindbarkeit von Open Educational Resources (OER) zu steigern. Metadatenkonsolidierung bedeutet, dass wir vorhandene Metadaten an Bildungsinhalten nach unseren strengen Qualitätskriterien überprüfen, ggf. anpassen und ergänzen.
Was Metadaten sind und was sie alles können, erfährst du in diesem Video.
Im Moment profitieren von dieser Arbeit vor allem die Lehrenden und Lernenden, die auf WirLernenOnline.de Inhalte suchen. Dank unserer umfangreichen Metadaten können sie so sehr schnell genau die Lern- und Lehrinhalte finden, die sie gerade brauchen.
Aber hier soll es nicht aufhören – wir möchten die Ergebnisse unserer Arbeit als Metadatenkonsolidierungsservice gerne auch wieder zurück in die OER-Community bringen, also zu den Organisationen und Menschen, die OER Inhalte erstellen und teilen. Das heißt: Wir möchten die Metadaten, mit denen wir die Inhalte für unser Portal anreichern, an die ursprüngliche Quelle zurückgeben. Dies sind meist deutlich mehr Metadaten als vorher, was die Sortierbarkeit und Auffindbarkeit der Inhalte in jedem Fall verbessert.
Der Workshop zu guten Metadaten
Unsere Idee für den Sommercamp-Workshop war es nun, diese Metadaten mittels einer API an die OER-Quellen zurückzugeben. Das bedeutet, dass OER-Anbieter*innen die Möglichkeit haben, diese Metadaten automatisiert abzurufen und nach ihren eigenen Vorstellungen weiter zu nutzen.
So können mit unseren zugegebenen Metadaten zum Beispiel:
- informative Daten wie bspw. die Lesezeit direkt am Inhalt angezeigt werden,
- Daten, die nur für Suchmaschinenbots lesbar sind, um die Auffindbarkeit in Suchmaschinen zu verbessern, angegeben werden
- etc.
Zahlreiche weitere Anwendungsfälle sind denkbar, und wir sind gespannt darauf zu sehen, wie die OER-Community diese Möglichkeiten nutzen wird.
Die Partner
Bei der Umsetzung unserer Idee haben wir großartige Partner an unserer Seite gehabt. ZUM, die älteste der deutschen OER-Communities, hat sich bereit erklärt, mit uns zusammenzuarbeiten. Wir haben uns im Vorfeld mit den IT-Dienstleistern von idea-sketch, Jan und Uwe, in Verbindung gesetzt und ihnen von unserer Idee erzählt. Sie waren begeistert und wollten gerne mitmachen. Auch Kulla von Serlo – ein weiterer großer Anbieter von OER Inhalten – fand das Thema interessant und schloss sich uns an. Die Metaventis GmbH baute die passende neue edu-sharing-Schnittstelle und beriet uns mit der ganzen Erfahrung aus vielen Jahren Inhalte-Crawling. An Bord hatten wir dann noch Jason von der GWDG, der sich insbesondere mit einem spannenden Seitenstrang auseinandersetzen, dazu weiter unten mehr.
Mehr Infos zum Konzept des Sommercamps findest du hier.
Der Ablauf
Nach einem gemütlichen Ankommen und Kennenlernen ging es am Montagnachmittag direkt los. Bei bestem Wetter saßen wir draußen im Garten und haben die Grundidee besprochen.
Jan und Uwe machten sich daran, nach bereits existierenden Lösungen in der MediaWiki-Plugin-Welt zu recherchieren, während wir uns in Absprache mit der Metaventis GmbH die neuen Schnittstellen in edu-sharing angesehen und getestet haben.
Es konnten noch kurzfristig Anpassungen gemacht werden, sodass wir schnell eine Schnittstelle nutzen konnten, die uns zu einer gegebenen URL die passenden Metadaten liefert.
Zur gleichen Zeit hat sich Jason dem Thema der persistenten IDs für OER gewidmet. Das Ziel war es herauszufinden, ob bestehende ID-Systeme analog zu ISBNs oder DOIs auch für Bildungsinhalte verwendet werden können. Für eine Vernetzung und den Datenaustausch über verschiedene Quellen und Datensammelstellen hinweg ist es notwendig, die Inhalte eindeutig identifizieren zu können. Mit welchen technischen Mitteln das gehen kann, sollte hier ermittelt werden.
Die Ergebnisse
Mit der lauffähigen Schnittstelle konnten Jan und Uwe technische Lösungen implementieren und ausprobieren. Unterbrochen nur von Essenspausen, einer unterhaltsamen Stadtführung und spannenden Lightning Talks arbeiteten wir bis in den lauschigen Dienstagabend, als der Proof of Concept (PoC) schließlich umgesetzt war. Am Beispiel des Klexikon vom ZUM konnte ein dynamischer Abruf der Metadaten installiert und die Integration dieser in die Artikel auf Klexikon.de erreicht werden.
Wir konnten zeigen, dass sich OER-Anbieter die auf WirLernenOnline.de angereicherten Metadaten zu ihren Inhalten auf relativ einfachem Wege in ihre Systeme und Inhalte holen können.
Diskussionen und Herausforderungen
Natürlich haben wir auch einige Herausforderungen identifiziert, die in Zukunft weiter untersucht und gelöst werden müssen:
- die Vermeidung von Metadaten-Generierung in einem endlosen Kreislauf
- die Frage nach der “single source of truth” für Metadaten
Wir haben auch diskutiert, wie die OER-Anbieter Einfluss auf die Metadaten nehmen können, die sie von unserem Service erhalten. Sie sind natürlich nicht verpflichtet, die automatisch generierten Daten unverändert zu übernehmen.
Stattdessen können sie zum Beispiel die Community-Redaktions-Umgebung bei WirLernenOnline.de nutzen, um die Metadaten ihrer Inhalte selbst zu bearbeiten und Qualitätssicherung durchzuführen.
Schlusswort rund um Metadaten und OER-Verlag
Ein herzliches Dankeschön geht an alle, die sich auf unser Experiment eingelassen und mit ihrem Interesse, ihren Vorarbeiten und natürlich auch der Teilnahme zum Gelingen des Workshops beigetragen haben.
Wir haben ein cooles erstes Ergebnis geschaffen, auf dem man weiter aufbauen kann. Das OER Sommercamp 2023 war eine wunderbare Gelegenheit, die Stärken der Community zu nutzen und gemeinsam an spannenden Projekten zu arbeiten. Wir freuen uns schon auf das nächste Jahr 🙂.
Zum Autor

Manuel leitet unser Team 4, welches bei uns für gute Daten und gute HUB-/Service-Technologien zuständig ist. Er bewahrt den Überblick über die vielfältigen Arbeitsbereiche des Teams, sorgt für Handlungsfähigkeit und steuert die Aktivitäten hin zu bestmöglichen Ergebnissen.
Sein Motto: Wenn du nur eine Lösung kennst hast du das Problem nicht verstanden.
Er kam im Juni 2022 ins Team, nachdem er vorher viele Jahre als Softwareentwickler gearbeitet hat.